
The Anatomy of a Modern NOC Operation
How to structure network operations so problems get solved at the right level, by the right people, the first time.


From Jim Martin, VP of Technology, Managed Services at INOC & Xerox IT Solutions
Most NOCs we’ve walked into over the past 20 years share the same basic problem. It’s not the tooling or the talent. It’s the structure.
The typical NOC is a room full of engineers who all do roughly the same thing. An alarm fires, whoever is available picks it up, works it until they either solve it or get stuck, and then escalates it to someone more senior. The senior person drops what they were doing, takes over, and works it from there.
Rinse, repeat, all shift, every shift.
This works when you’re monitoring a few hundred devices. It stops working when you’re monitoring thousands, across multiple clients, with different SLAs, different severity tiers, and different escalation requirements. At that scale, the “everyone does everything” model means your most experienced engineers spend most of their time on routine issues that a less senior person could have handled. Your P1 response is inconsistent because whoever happens to be free gets the critical incident. And your Tier 1 engineers never develop because they escalate anything that doesn’t match a pattern they’ve seen before.
The fix isn’t better tools. It’s a better operating structure.
What a well-structured NOC actually looks like
At INOC and Xerox IT Solutions, we've spent years developing what we call the Structured NOC. It's the operational framework we use to deliver 24x7 support across enterprise, service provider, and OEM environments.
The diagram below shows how it's organized.
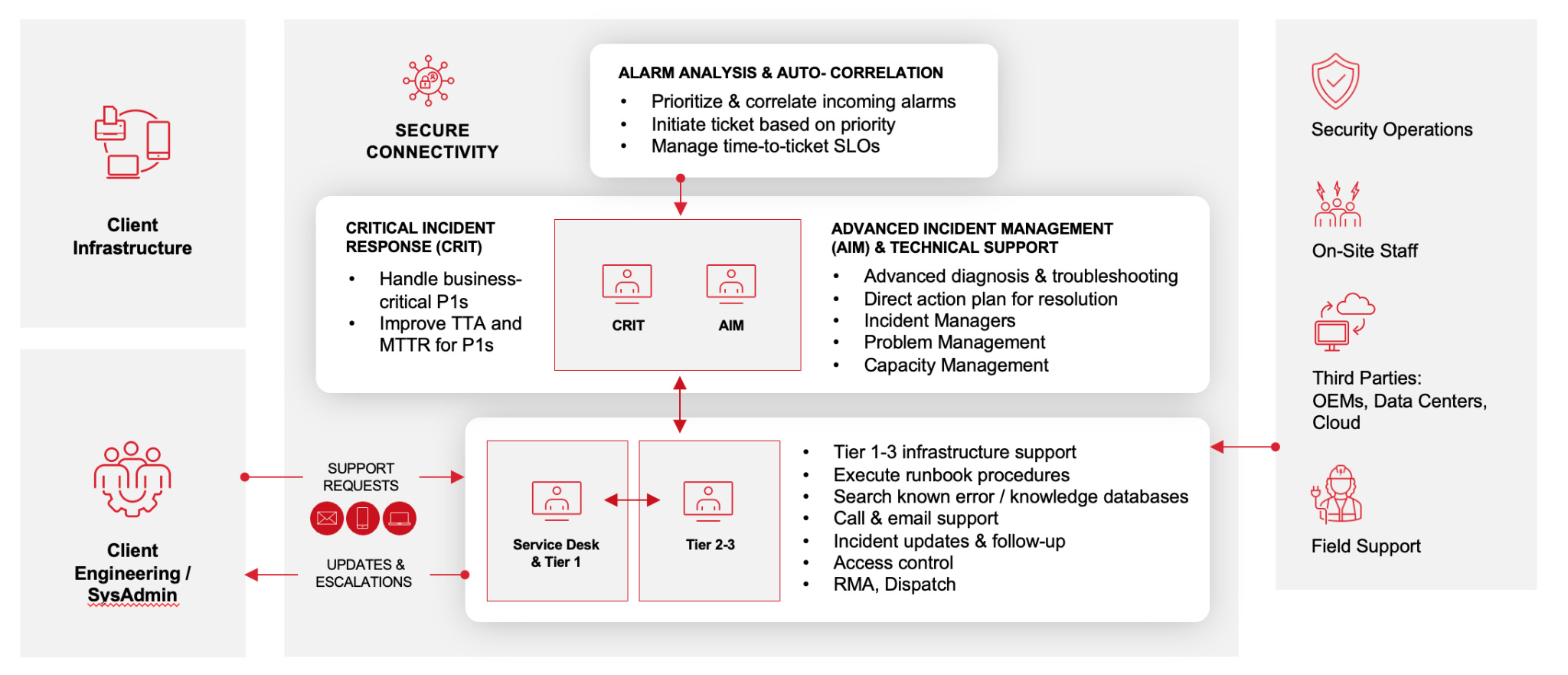
The structure has distinct operational layers, each with a defined scope of responsibility, and clear routing between them.
Alarms enter from the top.
Support requests enter from the bottom left.
Everything flows through defined paths to the right people at the right tier.
Here’s how each layer works, and more importantly, what the client gets from each one.
The front door: alarm analysis and auto-correlation
Everything starts here. Alarms and events from client infrastructure flow into the platform through secure connectivity. Before a human touches anything, the AIOps engine processes the incoming data.
At this stage, three things happen:
The engine prioritizes incoming alarms based on the client’s business impact rules.
It correlates related alarms so that 50 alerts from one fiber cut become one incident, not 50 tickets.
And it initiates the ticket based on priority, with the right SLA clock already running.
This layer manages time-to-ticket SLOs. The time between an alarm firing and a ticket being created in ServiceNow, enriched with CMDB data and ready for an engineer, is measured in seconds. In our environment, the target is under 30 seconds from alarm to a fully contextualized ticket.
The outcome of this is engineers not being buried in noise. The correlation engine has already done the work of separating signal from noise, grouping related events, and attaching the context an engineer needs to act. The ticket volume the NOC team actually works reflects the real incident volume, not the raw alert volume. That distinction is the difference between a NOC that’s drowning and one that’s focused on the incidents that are of the highest priority.
The triage layer: Advanced Incident Management
This is where the Structured NOC model differs most from traditional operations, and where I'd argue the biggest value lives.
In a traditional NOC, incidents enter at the bottom of the org chart. Tier 1 picks up the ticket, tries to resolve it, and escalates when they can’t. The senior engineers sit at the top and wait for escalations. By the time a complex incident reaches someone with deep diagnostic experience, it may have been misdiagnosed once or twice, bounced between tiers, and accumulated hours of elapsed time.
We inverted that. Our Advanced Incident Management (AIM) team sits at the beginning of the workflow, not at the end. These are senior troubleshooting personnel whose job is to look at every incoming incident (particularly P1s and P2s) and do four things:
Determine the exact nature of the problem.
Assess the full scope of impact.
Create a clear action plan for resolution.
Route the incident to the correct resolution team.
The AIM team also handles problem management and capacity management. They’re the people who look across incidents over time and identify patterns: recurring failures on the same circuit, capacity trends that predict future problems, chronic issues that need root cause analysis rather than repeated break-fix.
Our NOC clients get their incidents correctly diagnosed and routed from the start. The most common failure mode in NOC operations is misdiagnosis at initial triage, which causes the incident to bounce between teams, accumulate elapsed time, and frustrate everyone involved. The AIM model eliminates that by putting experienced analysts at the front.
Time to Impact Assessment (TTIA) drops because the person doing the assessment actually knows what they’re looking at.
We track TTIA as a formal metric here. It measures how quickly we can tell the client: here’s what’s happening, here’s what’s affected, and here’s what we’re doing about it. In a P1 situation, that communication is often more valuable to the client than the resolution itself, because it eliminates the uncertainty that causes organizational anxiety during an outage.
Critical Incident Response
When a P1 hits, it gets special handling. Our Critical Incident Response (CRIT) team is a dedicated group focused exclusively on business-critical outages. The client is hard down. Operations have stopped. The CRIT team’s job is to improve Time to Action (TTA) and Mean Time to Resolution (MTTR) for these incidents specifically.
CRIT operates alongside AIM but with a narrower focus: get the client back up. They have direct escalation paths, pre-established communication channels with the client’s leadership, and the authority to pull in whatever resources are needed (internal or external) without going through a queue.
The reason this needs to be a separate function rather than “everyone handles P1s” is consistency. When P1 response is distributed across the general population of engineers, the quality and speed of response depend on who happens to be on shift.
When it’s a dedicated team with defined procedures, the response is the same at 3 am on a Sunday as it is at 10 am on a Tuesday.
This nets out into a consistent, rapid response to the incidents that matter most. The executive who calls during a major outage talks to someone whose entire job is managing critical incidents, not someone who was also handling three P3 tickets and a maintenance notification when the phone rang.
Service Desk and Tier 1: the workhorse
The bottom of the structure diagram is where most of the daily volume lives. The Service Desk and Tier 1 team handles the incoming support requests from client engineering and sysadmin teams (phone, email, chat), as well as the incidents that flow down from the alarm analysis layer after the AIM team has assessed and prioritized them.

Tier 1 work includes:
Executing runbook procedures
Searching known error and knowledge databases
Providing call and email support to end users and client engineers
Incident updates and follow-up
Access control management
Coordinating RMA and dispatch when hardware needs to be replaced or a technician needs to go on-site
The key operational metric at this tier is first-level resolution rate: what percentage of incidents get resolved without escalation. In our environment, that number is 85% or higher. Most teams we talk to who run their own NOCs see 40 to 60%, sometimes even less.
The difference comes from two things: the enriched ticket (which gives the Tier 1 engineer full context from the moment they open it) and the runbook library (which gives them a defined procedure instead of requiring them to improvise).
Our clients get fast, consistent resolution for the majority of incidents. When 85% of tickets resolve at Tier 1, the client’s experience is that most problems get fixed quickly by the first person who touches them. They’re not being bounced between teams or repeating the same information to three different engineers. The structure ensures that Tier 1 has the tools and context to resolve what they can, and a clean handoff path for what they can’t.
Tier 2 and Tier 3: the specialists
When Tier 1 can’t resolve an issue (the remaining ~15%), it escalates to Tier 2 or Tier 3. These are advanced technical specialists with deep domain expertise in specific technology areas like routing and switching, optical, wireless, cloud infrastructure, security, and voice.
The critical thing about this tier is utilization. In an unstructured NOC, your most skilled engineers spend 60 to 80% of their time on work that a Tier 1 engineer could handle. That’s expensive, and it means they’re unavailable when a genuinely complex problem comes in.
In the Structured NOC model, Tier 2/3 engineers spend their time on the incidents that actually require their expertise. Our framework typically reduces high-tier support activities by 60% or more, sometimes as much as 90%. We measure this by tracking how activities migrate between tiers over the first few months of a new client engagement.
When our clients have a complex problem that requires deep expertise, that expertise is available. The specialists aren’t buried in password resets and routine maintenance tickets. They’re actually working on the problems that need them.
The external connections
The right side of the diagram shows the operational integrations that extend beyond the core NOC team.
To run through them quickly:
Security Operations handles the cybersecurity monitoring and response layer. This connects to our MDR capabilities and, for clients using it, to the TriShield 360 cyber defense platform.
On-Site Staff and Field Support handle situations that require physical presence: hardware swaps, cabling, rack work, anything that can’t be resolved remotely.
“Third Parties” covers OEMs, data centers, and cloud providers. When an incident involves vendor equipment or a carrier circuit, the NOC opens and manages the vendor ticket, tracks the SLA, and coordinates the resolution. The client doesn’t have to chase their ISP or their hardware vendor directly. That coordination is part of the service.
It’s one point of contact for everything. When a circuit goes down and the carrier needs to dispatch a technician, the NOC handles that coordination.
When a switch fails under warranty and the OEM needs to ship a replacement, the NOC handles the RMA. The client’s internal team isn’t spending time on vendor management and ticket tracking across multiple providers. That work is absorbed into the NOC operation.
The migration effect
One of the things that validates this model is what happens during the first few months of a new client engagement. When we onboard a team, their incident distribution usually reflects the unstructured model they came from.
Too many incidents are escalating to high tiers. The Tier 1 resolution rate is low. Senior engineers are handling routine work. Time to resolution is inconsistent.
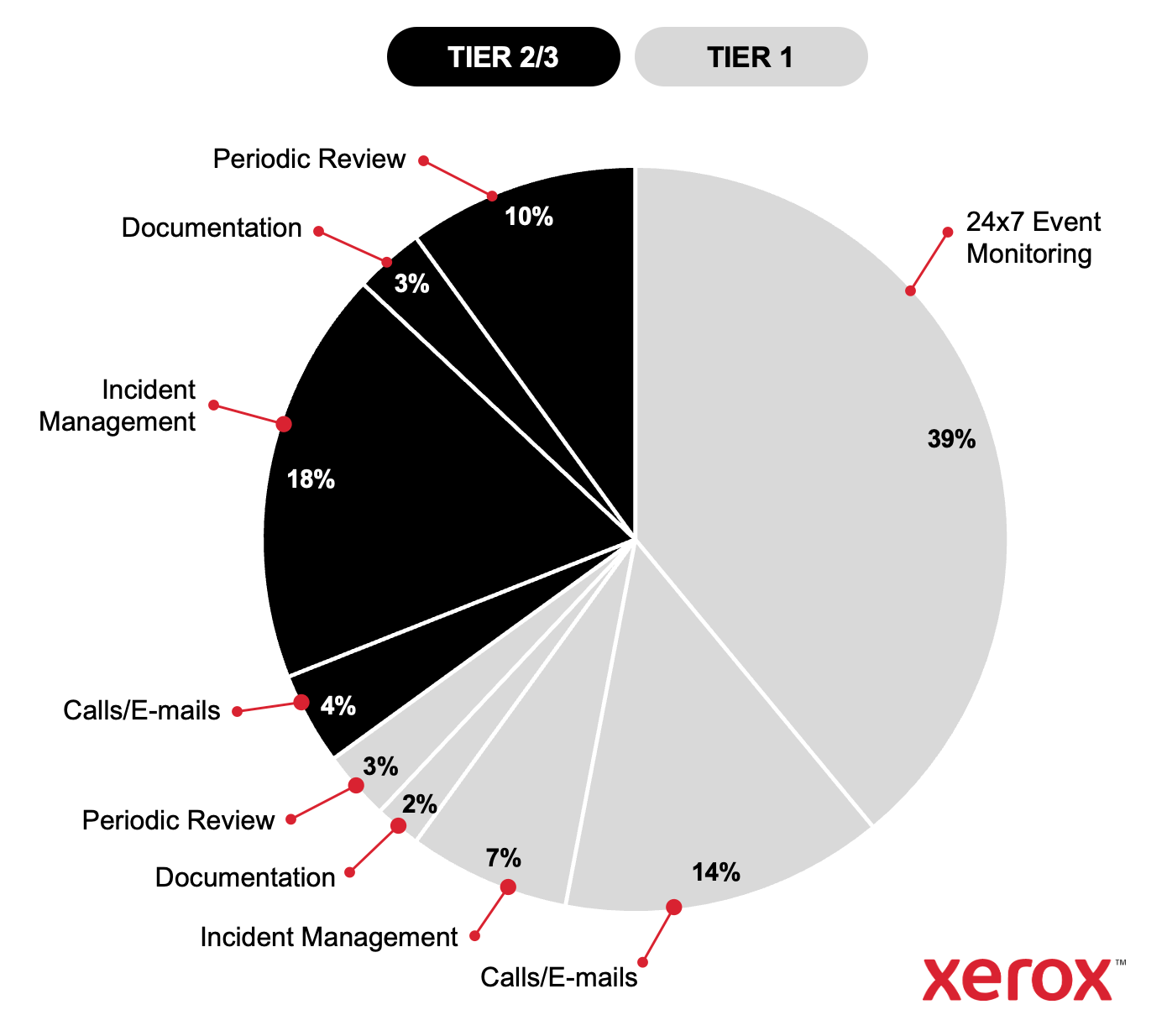
Over the first 90 to 180 days on the Structured NOC, activities steadily migrate to their appropriate tiers.
Tier 1 starts resolving more because the runbooks are built, the CMDB is populated, and the enriched tickets give them what they need.
AIM starts catching misdiagnoses earlier.
The auto-resolution rate climbs as the platform learns the client’s environment and more patterns qualify for automated remediation.
By the six-month mark, the distribution looks fundamentally different. High-tier activities have dropped by 60 to 90%. Tier 1 resolution is at or above 85%. Auto-resolution is handling nearly half of all incidents without human intervention. And the metrics (TTN, TTA, TTIA, MTTR) are tracking at levels the client has never seen from an internal operation.
At more or less full maturity, the numbers usually look like:
85%+ Tier 1 resolution rate.
48% auto-closed without engineer intervention.
45% reduction in time-to-action year over year.
Year-over-year cost reduction commitments of 5% in years 2 and 3 through AIOps maturation.
Why structure (in some ways) matters more than tools
We’ve been in this industry long enough to have watched multiple generations of NOC tooling come and go. SNMP managers, NMS platforms, ITSM systems, AIOps engines. The tools keep improving, but the NOCs that perform well have one thing in common: the operational structure is right.
A well-structured NOC with average tooling will outperform a poorly structured NOC with best-in-class tooling every time. The structure determines who handles what, how incidents flow, where decisions get made, and whether your most experienced people spend their time on the problems that need them or on the problems that just happen to land in their queue first.
The Structured NOC model we run is the result of two decades of building, measuring, and refining this structure across hundreds of client environments. It’s not the only way to organize a NOC. But the principles behind it, senior triage at the front, tiered resolution with clear escalation paths, automated correlation and enrichment feeding the human workflow, dedicated critical incident response, and continuous measurement driving improvement, are the principles that produce consistent, measurable results.
If you’re running a NOC internally and your Tier 1 resolution rate is below 60%, your senior engineers are spending more than half their time on routine work, or your P1 response quality depends on who’s on shift, the structure is the thing to fix. Not the dashboard and not the alerting rules. The structure.
If you want to see how this model would apply to your environment, get in touch. We’ll walk you through the operational framework and show you what the tier migration looks like for organizations similar to yours.

About INOC, a service of Xerox IT Solutions
INOC is an ISO 27001:2022 certified 24×7 NOC and an award-winning global provider of NOC Lifecycle Solutions®, including NOC support, optimization, design, and build services for enterprises, communications service providers, and OEMs. INOC solutions significantly improve the support provided to partners’ and clients’ customers and end users.
INOC assesses internal NOC operations to improve efficiency and shorten response times, and provides best practices consulting to optimize, design, and build NOC operations, frameworks, and procedures. Proactive 24×7 NOC support is provided with several options, including North America, EU, or APAC only or global integrated NOCs. INOC’s 24×7 staff provides a hands-on approach to incident resolution for technology infrastructure support.
Learn more about our NOC support and NOC operations consulting services. Get in touch to start the conversation. We’d love to talk NOC.