
Inside an AI-Enabled Network Operations Center
A brief tour of where and how machine learning and automation touch our NOC operation and service desk at the moment.


From Jim Martin, VP of Technology, Managed Services at INOC & Xerox IT Solutions
Most service providers who monitor and manage network infrastructure say they’re “AI-enabled” one way or another now. In practice, though, that usually means they’ve bolted on a dashboard or reporting tool that uses the word “intelligence” somewhere in the interface. Maybe they’ve got a couple of correlation rules. Maybe they’ve integrated GenAI into their ticketing.
Our NOC operations service, INOC, has been applying machine learning and automation to operations infrastructure for several years now. We call the result the Xerox INOC Platform 3.0. I’ll walk through the platform and give you a tour of how AI and automation actually show up in our operations and what they do.
This is going to be detailed! If you run a NOC or you’re evaluating one, this is the piece where you can compare claims against actual mechanics.
The Xerox INOC platform in 30 seconds
Before getting into the AI specifics, it helps to understand what the platform is. The Xerox INOC Platform 3.0 is our operating system for NOC and service desk delivery.
It has three major flows: alarm, ticketing, and notification.
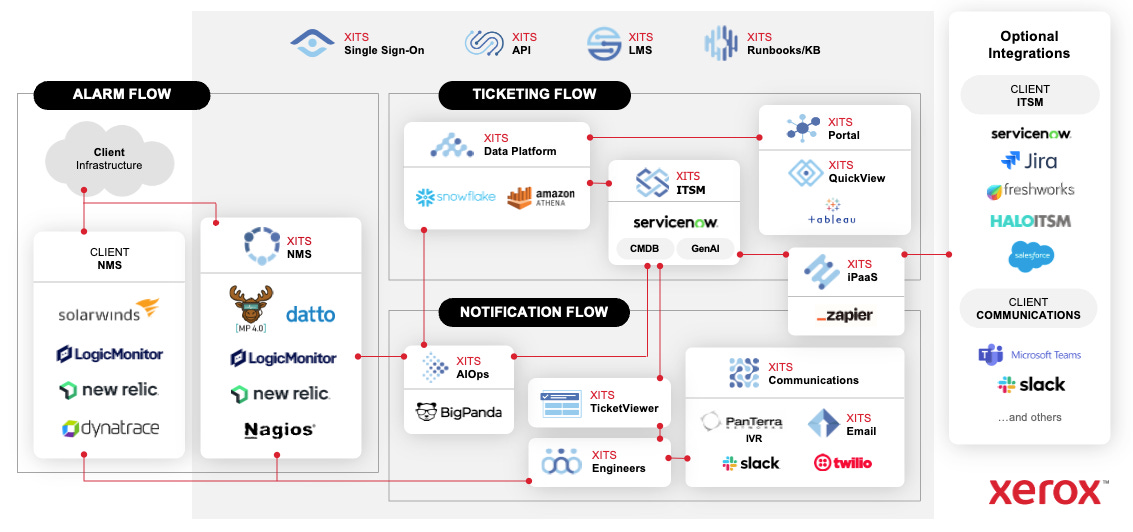
I’ll unpack this:
On the left side, client infrastructure and monitoring tools (LogicMonitor, SolarWinds, New Relic, Datto, Nagios, Dynatrace, whatever the client runs) feed alarm and event data into our AIOps engine.
That engine processes, correlates, and contextualizes that data. The output feeds into ServiceNow, our ITSM platform, where incidents are created, enriched from the CMDB, and worked by engineers. On the right side, integrations push data back into the client’s ITSM (ServiceNow, Jira, Freshworks, HaloITSM, Salesforce) and communications tools (Slack, Microsoft Teams, Twilio, email).
The whole process from alarm ingestion to an engineer holding a fully contextualized ticket can take under a minute. If you want the full deep-dive, stop here and read our platform explainer first.
This gives you an idea of the “shell.” Now here’s where AI, ML, and automation actually live inside it.
1. Event correlation
This is the core of our AIOps tooling, and it’s one of the platform’s biggest differentiators. A typical mid-sized environment can generate hundreds of events during peak hours. When a fiber line gets cut, 50 different devices might fire alarms in the same two-minute window. In a traditional NOC, that’s 50 tickets, 50 triage actions, and several engineers chasing what turns out to be one problem.
Our AIOps engine takes those 50 alarms, analyzes them against topology data and historical patterns, identifies that they’re all expressions of the same underlying incident, and generates one ticket. The engine is doing alarm correlation, pattern matching, and noise reduction in real time.
Rather than querying a static set of rules, we’re using extremely carefully trained AI to improve the correlation accuracy over time as we process more data from a given client’s environment. The more it sees, the better it gets at grouping related events and separating genuinely new issues from noise.
The operational impact is direct: engineers aren’t triaging 50 tickets. They’re triaging one! The cognitive load difference is enormous.
2. Automatic ticket creation and enrichment
Once the AIOps has correlated events into an incident, the system automatically creates a ticket in ServiceNow. This is where the CMDB does its work.
The incident ticket gets created with the following context already attached:
The affected device record.
The services that depend on it.
Related infrastructure and dependencies
The assigned support team.
Vendor contacts
Third-party details
Runbooks relevant to that incident type
Knowledge articles from the ServiceNow knowledge base.
All of that is pulled from the CMDB and linked in a few seconds.
In a traditional NOC, an engineer would spend the first 10 to 15 minutes of an incident gathering this information manually. By the time they opened the ticket, they’d be starting from nothing. In our environment, the engineer opens a ticket that already has everything they need.
This is automation and data integration, not machine learning specifically. But it’s the foundation that makes the ML-driven pieces (like correlation and self-healing) useful. Without the enriched ticket, the automation upstream doesn’t translate into faster resolution downstream.
3. Automatic ticket creation and enrichment
Not all incidents are equal, and our platform knows this. Each incoming incident gets classified by business impact and severity using the data the system already has about the affected services.
Our priority system runs Priority 1 (P1) through Priority 4.
A P1 means the client is hard down, no redundancy, operations are stopped.
A P4 is informational. The classification drives everything downstream: who gets notified, through which channels, with what urgency, and what SLAs apply. All of this happens automatically.
The AIM (Advanced Incident Management) team gets the P1s and P2s immediately. P3s and P4s route through standard queues.
Here’s a visual breakdown of our structured NOC operations with tiered workflows:
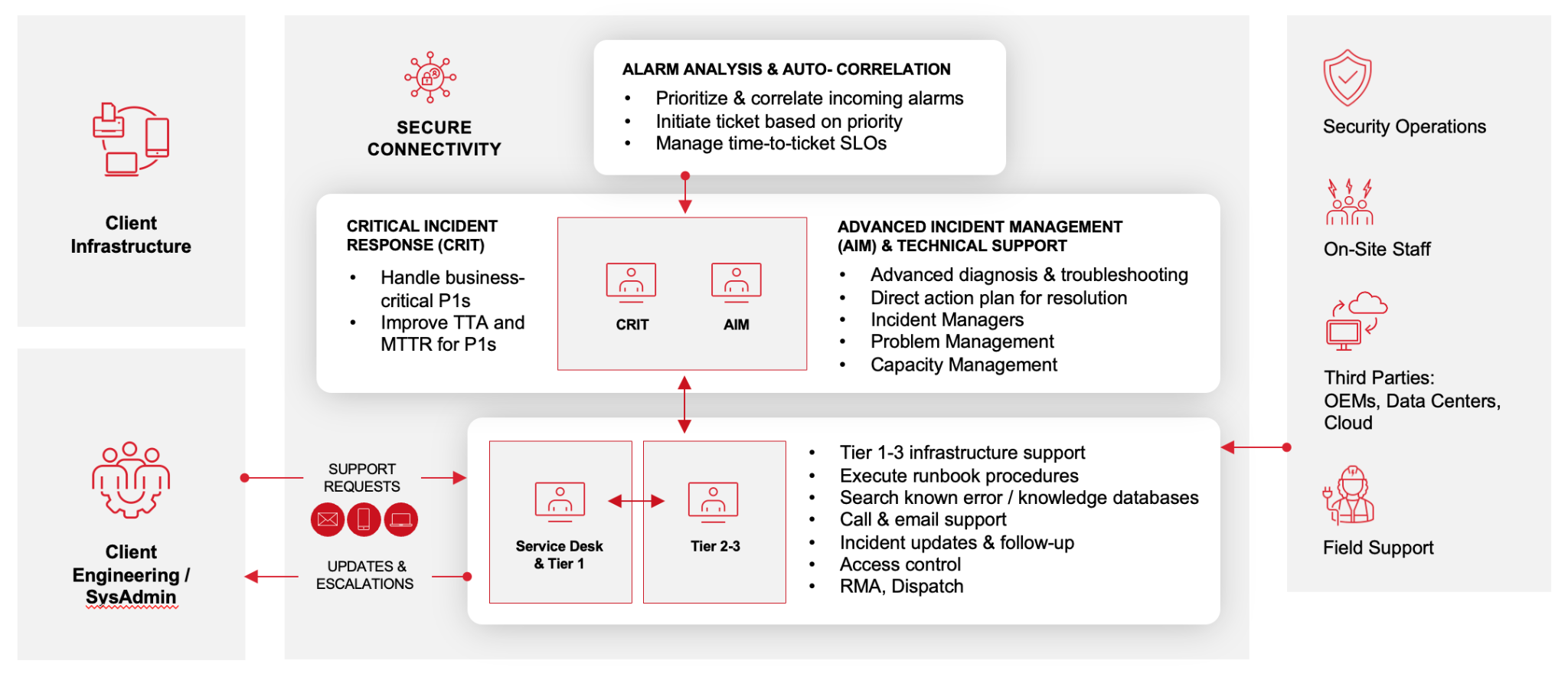
The prioritization also drives our notification workflows. Client stakeholders get notified through IVR (PanTerra), email, Slack, Twilio, or whatever other platform they use based on the priority tier and the client's notification preferences. Those notifications fire without anyone manually composing them.
4. Self-healing and auto-resolution
This is where things get interesting. For a growing class of routine operational issues, the platform doesn’t wait for an engineer.
It executes the remediation itself!
A couple of examples of what self-healing handles today:
A monitoring tool detects an access point is unresponsive. The platform logs into the upstream switch, disables the port, re-enables it to force a restart, and verifies service restoration. No human touches it.
On an optical network, an amplifier fails to register light properly. The platform toggles the laser, waits for the light level to normalize, and confirms the circuit is back. No human touches it.
Memory restarts, service restorations, certain types of configuration drift, predictable backup failures: these all have automated remediation paths. The platform detects the pattern, matches it against known resolution procedures, executes, validates, and closes.
We now typically auto-close 48% of incidents without an engineer touching them.
5. Recurring event handling
This is an automation function that sometimes gets overlooked but saves a lot of time. A feature called Recurring Event Handler separates events that have already been associated with an existing ticket from events that are genuinely new.
When a device flaps, or an issue recurs while a ticket is still open, the platform auto-associates the new event with the existing ticket, acknowledges the alarm, and logs the correlation (engineers don’t get a second ticket for the same problem). This directly reduces mean time to resolution because it stops the NOC from treating a recurring symptom as a new incident. This is one of the most common issues in NOCs and other support functions that drive people crazy while really dragging down service levels.
6. Automated runbook execution
Runbooks are step-by-step troubleshooting procedures.
Here’s the basic “anatomy” of our typical NOC runbook:

Traditionally, an engineer would open a runbook, follow the steps, and document what they found. We’ve automated the first diagnostic steps for many incident types.
When an incident is created, the platform can automatically locate affected infrastructure elements, retrieve relevant event data, run initial diagnostics, and update the ticket with the findings. By the time a human engineer opens the ticket, the first phase of investigation is already done.
This is rule-based automation, not ML. But the benefit compounds with the correlation and enrichment pieces. The ticket arrives with context, the diagnostics have already started, and the engineer can skip the research phase and go straight to resolution.
7. GenAI
We’ve been working generative AI into ServiceNow, which is our platform’s platform so-to-speak.
The most production-ready application we have in our NOC service today is really tight ticket summarization.
When a complex incident spans days, involves shift changes, and accumulates dozens or hundreds of updates, the ticket history becomes a document in itself. An engineer joining mid-incident has to read through all of it to understand what’s happened, what’s been tried, and where things stand. GenAI condenses that history into a concise summary: what happened, what was done, what’s still open. The engineer reads a few paragraphs instead of scrolling through 80 ticket updates.
This is a genuine time savings. Anyone who has worked a long-running P1 knows how much context gets lost at shift boundaries.
The broader GenAI roadmap is what we’re calling 4.0. It might include things like:
Automatic knowledge article generation from resolved incidents (so the system learns from every ticket it closes).
On-the-fly runbook creation when no runbook exists for a given pattern.
Automated action plan generation.
Agentic workflow execution where the AI doesn’t just suggest remediation but executes it.
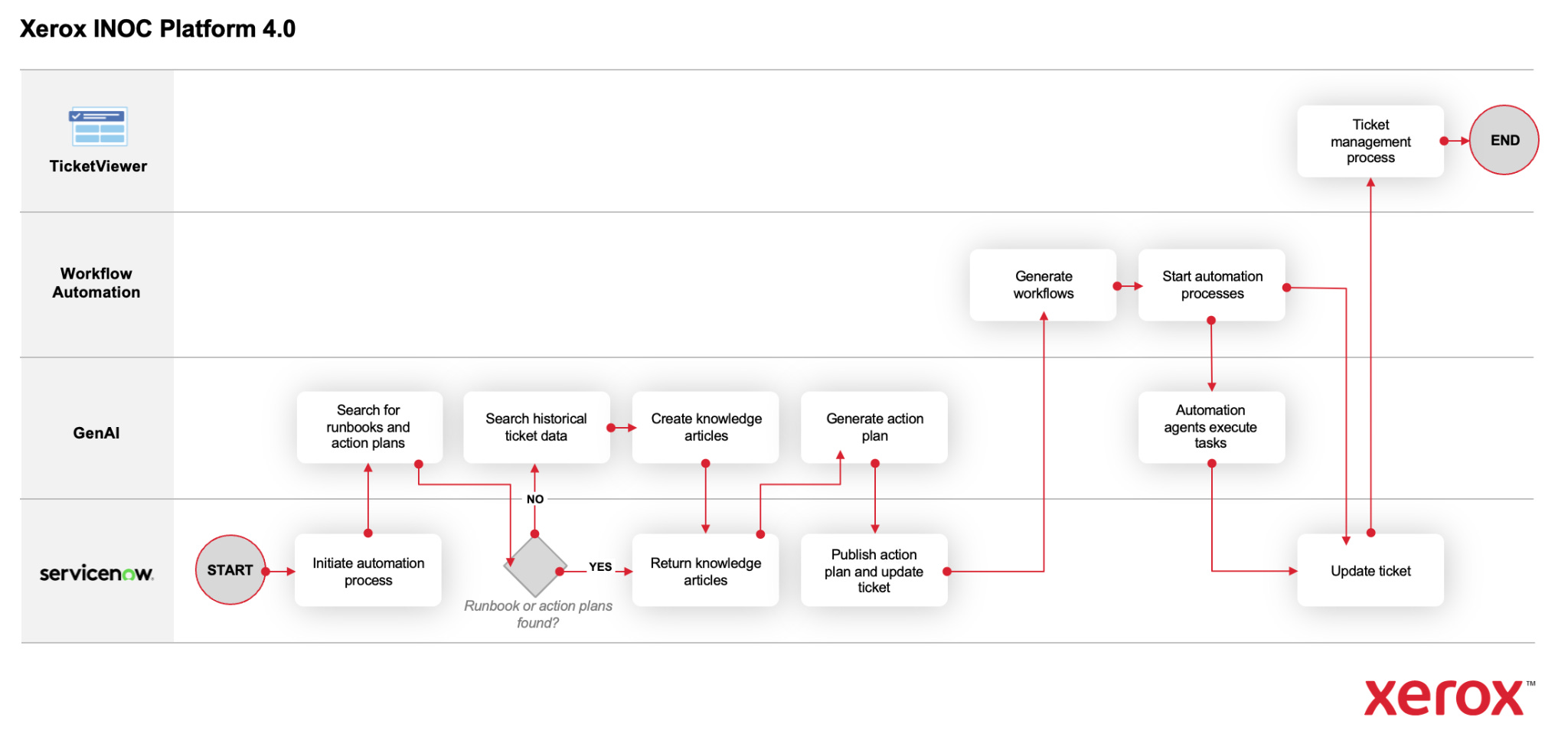
Platform 4.0 is in development. The GenAI applications beyond ticket summarization are still maturing. We're testing, validating, and refining.
8. Change management automation
Maintenance windows are common hurdles in NOC operations. Every time a client schedules maintenance on a device or circuit, the NOC needs to know about it to avoid creating false incidents from expected alarms. Unsurprisingly, the NOC isn’t notified as much as it would like to be.
The platform handles this automatically. When a maintenance event is recorded, alarm suppression activates for the affected configuration items. The system only creates tickets if something fires after the maintenance window closes, or if an unexpected alarm occurs during the window. The system also ties maintenance records back to configuration items, so future incidents can be correlated with recent changes.
This is one of those capabilities that’s invisible when it works and painful when it doesn’t. Maintenance-related false alarms are a significant source of noise in any NOC. Automating the suppression removes that category of waste.
9. Problem management and predictive analytics
AIOps can be used for much more than just attacking incidents. It also drives problem management by spotting patterns across incidents over time.
When the same type of incident recurs on the same circuit, device, or vendor, the platform surfaces that trend. Our reporting provides visibility into incident volumes, resolution times, categorization patterns, and infrastructure hot spots.
Clients can see which carrier circuits experience the most outages, which hardware components fail most frequently, and which categories of incidents consume the most engineering time.
The predictive element is still developing alongside the tooling available to us. We can identify patterns that precede failures (CPU trends, capacity curves, degradation trajectories) and flag them before they cause an outage. The accuracy depends on having enough historical data from a client’s environment. For clients who have been on the platform for a year or more, the pattern library is substantial.
10. Help desk applications
The help desk side is where GenAI has the most untapped potential. The help desk is (arguably) more ripe for AI than the NOC was, because the tickets are more repetitive and the workflows are more standardized.
The actual logistics of help desks are different than the NOC in ways that complicate integration, but here’s the direction we’re heading:
AI reads resolved help desk tickets, identifies the most common issue types, and generates knowledge articles and self-service content from the resolution data.
If 1,000 out of 1,500 tickets are due to the same password reset or software configuration problem, the system identifies that pattern and builds documentation to prevent it from becoming a ticket next time.
We're also working on smarter routing, where AI classifies incoming requests and sends them directly to the right tier or specialist, skipping the generic intake process. Executives get faster escalation. Engineers skip Tier 1 and go directly to Tier 2. Apple-specific issues go to a dedicated Apple support team, for example.
What the numbers look like
A few operational metrics that are downstream of these capabilities give some hard insight into how this all translates into actual value:
85% or more of incidents resolved at Tier 1.
48% of incidents auto-closed without an engineer touching them.
45% reduction in time-to-action year over year.
Year-over-year cost reduction contractually committed: 5% in year 2, 5% in year 3, driven by AIOps maturation.
These numbers came from the AIOps and automation investments described above. Each improvement connects to a specific capability: correlation reduces noise, enrichment reduces research time, auto-resolution reduces ticket volume, runbook automation reduces diagnostic time.
What “AI-enabled” actually means in the NOCs of today
If you’ve read this far, you have a concrete picture of where AI, ML, and automation live in a modern NOC platform.
Here’s how I’d summarize it:
AI-enabled doesn’t mean the NOC runs itself. It means the platform handles the parts of operations that don’t need a person: event correlation, ticket creation, data enrichment, routine diagnostics, known-pattern remediation, stakeholder notification, and report generation.
It means the parts that do need a person (complex troubleshooting, vendor coordination, architectural decisions, client communication during outages) get better because the person starts with full context instead of a blank screen.
The humans aren’t going away! They’re going to spend less time doing things machines are better at and more time doing things that actually require judgment and expertise. It’s operational, and it’s already running.
If you want to see what this looks like on real infrastructure, get in touch. We’ll show you the platform and walk you through the data.
📄 Also, be sure to read our free white paper that digs into the NOC and ITOps side of this a little deeper: The NOC Improvement Playbook — 10 Common Problems We See and Solve in Our Consulting Engagements

About INOC, a service of Xerox IT Solutions
INOC is an ISO 27001:2022 certified 24×7 NOC and an award-winning global provider of NOC Lifecycle Solutions®, including NOC support, optimization, design, and build services for enterprises, communications service providers, and OEMs. INOC solutions significantly improve the support provided to partners’ and clients’ customers and end users.
INOC assesses internal NOC operations to improve efficiency and shorten response times, and provides best practices consulting to optimize, design, and build NOC operations, frameworks, and procedures. Proactive 24×7 NOC support is provided with several options, including North America, EU, or APAC only or global integrated NOCs. INOC’s 24×7 staff provides a hands-on approach to incident resolution for technology infrastructure support.
Learn more about our NOC support and NOC operations consulting services. Get in touch to start the conversation. We’d love to talk NOC.